

How Can You Protect Your Cloud Applications From Outages?
How Can You Protect Your Cloud Applications from Outages?
Were you affected by the Amazon Web Services (AWS) outage this week? If you use Quora, Slack or Trello chances are you were. S3 Storage services in the US-East region was essentially unavailable for 4-5 hours. Since many other AWS services and customer applications depending on S3, this large cloud applications outage had a wide-ranging impact across many services, sites and applications.
Some popular sites that were affected included:
- Quora
- Business Insider
- Trello
- Slack
- Giphy
- Medium
- US Securities and Exchange Commission
Ironically, even the AWS status page that reports on the status of various AWS services was affected. In the brave new world of IoT devices everywhere – often relying on cloud services to operate – this resulted in people being unable to control the lights in their home or their thermostats, and there was even a story where an IoT home alarm was going off and they were unable to turn it off.
How Can You Protect Your Azure Applications?
No cloud provider is immune to outages – in fact Azure had a similar outage with Azure Storage Accounts a couple of years ago that had a wide-ranging impact. However, there are actions that software teams can take to minimize the risk of outages, and provide a high level of availability even in the face of infrastructure outages.
Azure provides a robust set of options for designing and deploying applications for high availability. If used appropriately, this would allow your applications to survive outages like the AWS S3 outage this week.
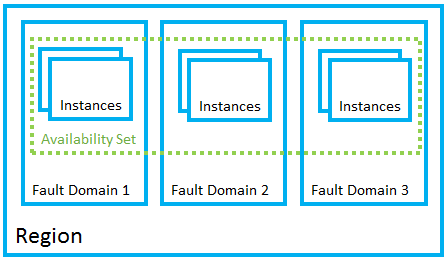
Availability Sets
If your application uses an IaaS model with Azure VM’s, you can configure multiple redundant VM’s into Availability Sets, which automatically spread the VM’s across what Azure calls Fault Domains and Update Domains. Fault Domains ensure there is no shared hardware (servers, power providers, network providers) between the VM’s, protecting your application from hardware failures. Azure uses Update Domains to coordinate updates that may result in VM reboots, such that only some of the VM’s inside an availability set are rebooted at the same time, ensuring your application remains available at all times. If you use Azure Managed Disks – a relatively new service – it also ensures that the disks your VMs use are isolated from each other across different “stamps”, ensuring that hardware failures only affect some but not all of the VM/disks.
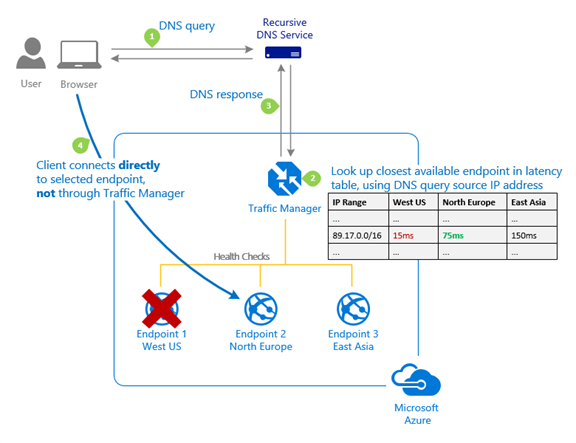
Traffic Manager
To protect against an entire Azure Region outage, you can create multiple redundant copies of your Web Sites and/or VM’s across multiple Azure Regions. Azure Traffic Manager provides an intelligent convenient method of load balancing the traffic across those resources and regions. It can monitor and detect when services or entire regions become unavailable,/image automatically redirecting traffic to the healthy services. It can also direct traffic to the region closest to the actual user – useful even when everything is healthy.
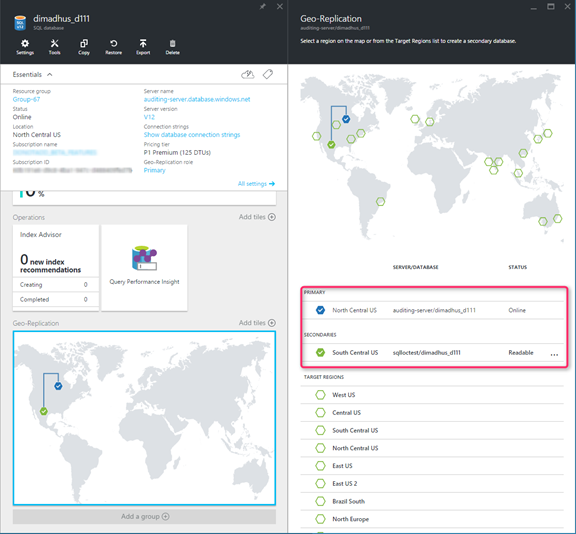
SQL Database Geo-Replication
When using Azure SQL Databases, you can configure Geo-Replication to protect against any region-specific outages. Even without Geo-Replication, SQL Databases are protected against hardware failures within a datacenter by having three separate copies of the data spread across isolated hardware within the same datacenter. With Geo-Replication you can ensure your database remains available even if an entire Azure Region/Datacenter suffers an outage. Geo-Replication maintains multiple copies of your database in multiple Azure regions (up to five different regions), and keeps them up-to-date automatically. If an outage occurs, there is an easy mechanism to failover your database to one of the replicated secondary regions.
Geo-Redundant Storage
When using Azure Storage Accounts, even the least expensive tier (LRS) automatically creates three copies of your data spread across separate fault domains and update domains within the same data center. To achieve even higher resiliency, you can opt for Geo-Redundant Storage (or RA-GRS) which replicates your data across two Azure regions, storing three copies in each region/data center.
By making appropriate use of the above Azure services and architecting your application infrastructure for high availability, even severe cloud outages like the one AWS experienced can be mitigated ensuring your applications remain available for your customers.
Of course, even the most well-thought-out architectures and careful deployments need to be tested. If you’re striving for high availability – able to survive even a region-wide outage – the only way to know whether you’ve been successful is to wait for the next outage and pray or plan and run tests proactively to test your applications.
Netflix in particular, has been doing some amazing things in regards to testing their ability to handle unexpected outages. They created a tool called Chaos Monkey – which later evolved into a suite of tools such as Chaos Gorilla, Chaos Kong, Latency Monkey, etc. These tools run continuously in their production environment, constantly triggering random outages, shutting down servers and other systems to ensure that the automated detection and failover systems are working properly. Chaos Kong, for example, will take down an entire region – IN PRODUCTION!
Next Steps to Avoid Cloud Applications Outage
If you are planning to move your applications to the cloud – or have existing applications in Azure – let us help you plan, architect, and implement your applications to ensure they remain highly available even in the face of Azure outages.
Thank you for reading this post! If you enjoyed it, I encourage you to check out some of our other content on this blog. We have a range of articles on various topics that I think you’ll find interesting. Don’t forget to subscribe to our newsletter to stay updated with all of the latest information on Imaginet’s recent successful projects
discover more

The Imaginet Difference: Boutique In Size with Big Results
The Imaginet Difference: Boutique In Size with Big Results April 09, 2024 Since 1997, Imaginet has been a proud Microsoft Partner. We offer a variety of Microsoft-related consulting, implementation, and…

QR Code Phishing Attacks: Are You Protected?
QR Code Phishing Attacks: Are You Protected? April 09, 2024 QR code phishing attacks or “Quishing” are on the rise, and it’s crucial to raise awareness about this evolving threat.…

Virtual Workspaces Are Here! How Will You Use Them?
Virtual Workspaces Are Here! How Will You Use Them? April 4, 2024 My YouTube feed has been full of reviews of the Apple Vision Pro since it became available in…
Let’s build something amazing together
From concept to handoff, we’d love to learn more about what you are working on.
Send us a message below or call us at 1-800-989-6022.